深入理解JVM内存划分 数据处理与存储服务的核心基石
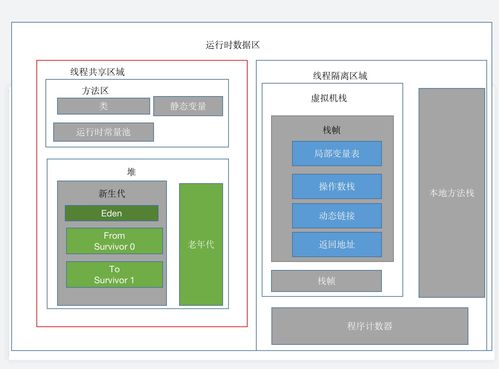
Java虚拟机(JVM)的内存划分是Java程序运行的底层基石,对于构建高性能、高可靠的数据处理和存储服务至关重要。JVM通过精细的内存管理机制,为数据操作提供高效的执行环境和稳定的存储空间。
JVM内存主要划分为以下几个核心区域:
1. 程序计数器(Program Counter Register)
作为线程私有的内存区域,程序计数器记录当前线程执行的字节码指令地址。在数据处理任务中,多线程并发执行时,它能确保线程切换后能恢复到正确的执行位置,保障数据处理的连续性。
2. Java虚拟机栈(Java Virtual Machine Stacks)
同样为线程私有,每个方法执行时会创建栈帧,存储局部变量表、操作数栈等信息。对于数据处理服务,栈深度控制和方法调用链路的优化能显著提升计算效率。
3. 本地方法栈(Native Method Stacks)
为JVM调用本地(Native)方法服务,在涉及底层存储操作或高性能计算时发挥作用。
4. Java堆(Java Heap)
这是数据处理和存储服务最关键的内存区域。所有对象实例和数组都在堆上分配,它被所有线程共享。现代JVM将堆进一步细分为:
- 新生代(Young Generation):存放新创建的对象,分为Eden区和两个Survivor区。数据处理中大量临时对象的创建和回收主要发生在此区域。
- 老年代(Old Generation):存放长期存活的对象,如缓存数据、连接池对象等核心服务组件。
- 元空间(Metaspace,JDK8+):存储类元数据,替代了早期的永久代(PermGen)。
堆的垃圾回收机制(如Serial、Parallel、CMS、G1等收集器)直接影响数据处理服务的吞吐量和延迟。合理的堆大小设置和垃圾回收器选择是优化存储服务性能的关键。
5. 方法区(Method Area)
存储已被加载的类信息、常量、静态变量等。在数据处理服务中,大量业务类和数据转换类的加载与此区域密切相关。
6. 直接内存(Direct Memory)
并非JVM规范定义的部分,但通过NIO的DirectByteBuffer可直接分配堆外内存。这在数据处理和存储服务中极为重要,能减少Java堆与Native堆之间的数据复制,显著提升大文件读写、网络传输等I/O操作的性能。
在数据处理和存储服务中的应用与优化
- 大数据处理:在Spark、Flink等计算框架中,合理设置堆内存和直接内存比例,能有效平衡计算与I/O开销。通过调整新生代与老年代比例,优化短生命周期数据对象(如中间计算结果)的回收效率。
- 缓存服务:如Redis的Java客户端或自研缓存系统,将热点数据存储在堆内存的老年代中,需注意防止内存泄漏和大对象导致的Full GC停顿。
- 数据库连接与存储:数据库连接池对象通常长期存活于老年代。使用直接内存处理网络缓冲和文件映射,能提升数据读写吞吐量。
- 序列化与反序列化:数据处理中频繁的序列化操作会产生大量临时对象。通过复用对象、使用堆外内存或更高效的序列化库(如Protobuf、Kryo),可减轻堆压力。
- 监控与调优:借助JVM工具(如jstat、jmap、VisualVM)监控堆内存使用、GC频率与耗时。针对数据处理负载特点,调整参数如
-Xmx(最大堆内存)、-Xms(初始堆内存)、-XX:NewRatio(新生老生代比例)等。
最佳实践建议
- 根据数据处理任务的特点(如批处理与流处理)选择匹配的垃圾收集器。例如,低延迟服务可考虑G1或ZGC。
- 对于需要操作大量原生数据的存储服务(如消息队列、文件存储),优先考虑使用直接内存,但需注意手动管理释放。
- 避免在业务代码中创建过大的对象或数组,以防止直接进入老年代引发提前GC。
- 利用软引用(SoftReference)和弱引用(WeakReference)实现内存敏感缓存,在内存紧张时自动释放。
理解JVM内存划分不仅是Java开发者的基本功,更是构建高效、稳定数据处理与存储服务的必备知识。通过合理配置和持续调优,JVM能够为各类数据密集型应用提供强大的运行时支持。
如若转载,请注明出处:http://www.somaodata.com/product/61.html
更新时间:2026-06-19 19:05:13