Nacos注册中心 服务多级存储模型在数据处理与存储服务中的应用
随着微服务架构的普及,服务注册与发现成为系统设计的核心组件。Nacos作为阿里巴巴开源的一款动态服务发现、配置管理和服务管理平台,其独特的服务多级存储模型为数据处理和存储服务的高效运行提供了坚实的技术支撑。本文将深入探讨Nacos的服务多级存储模型,并分析其如何赋能数据处理与存储服务,实现高可用、高性能的服务治理。
一、Nacos服务多级存储模型解析
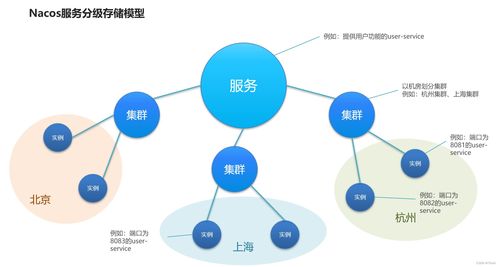
Nacos的服务存储模型采用分级设计,主要分为三级:服务(Service)-> 集群(Cluster)-> 实例(Instance)。
- 服务(Service):代表一个微服务应用,是最高级别的抽象。在数据处理场景中,一个数据处理服务(如数据清洗服务)或一个存储服务(如对象存储服务)均可注册为一个独立的Service。
- 集群(Cluster):同一服务下的逻辑分组,通常根据部署环境(如数据中心、机房)或功能划分。例如,一个数据处理服务可能分为“北京数据中心集群”和“上海数据中心集群”,以实现就近访问和容灾。
- 实例(Instance):服务的具体运行实例,包含IP、端口、健康状态等元数据。每个实例都属于一个特定的集群。在存储服务中,每个存储节点(如一个MinIO实例)就是一个Instance。
这种层级结构使得服务管理更加精细,支持基于集群的路由策略和负载均衡,为数据处理和存储服务的部署与扩展提供了灵活性。
二、在数据处理与存储服务中的具体应用
数据处理与存储服务通常对延迟、吞吐量和可用性有极高要求。Nacos的多级存储模型通过以下方式满足这些需求:
- 提升服务发现效率:当数据计算任务需要调用某个数据处理服务(如图像处理服务)时,客户端可通过Nacos快速获取该服务下健康实例的列表。通过集群划分,客户端可以优先选择同集群或低延迟集群的实例,减少网络开销,这对于大数据量的传输和处理至关重要。
- 实现智能路由与负载均衡:Nacos支持基于权重的负载均衡。在存储服务中,不同存储节点的负载和容量可能不同。管理员可以通过Nacos为每个实例设置权重,流量将按权重分配,从而避免单个节点过载,优化资源利用率。
- 增强容灾与高可用性:通过将实例分布到多个集群(如不同可用区),当某个集群发生故障时,Nacos的健康检查机制能迅速将故障实例标记为不健康,服务消费者会从列表中剔除这些实例,自动将请求切换到其他健康集群的实例上,保证数据处理流水线的连续性。
- 动态配置管理:除了服务注册发现,Nacos的配置管理功能可与存储模型结合。例如,可以为不同集群的数据处理服务配置不同的参数(如并发线程数),实现配置的精准下发,适应不同环境的性能要求。
三、数据处理与存储服务的最佳实践
- 集群按功能与地域划分:对于全球部署的数据处理服务,可按“地域”(如us-east, eu-central)划分集群。对于存储服务,可按存储类型(如“热存储集群”、“冷存储集群”)或性能等级划分,便于管理和路由。
- 元数据丰富化:在注册实例时,充分利用Nacos的元数据(Metadata)字段。例如,为存储服务实例添加“总容量”、“已用容量”、“IOPS”等自定义标签。消费者端可以根据这些元数据进行更智能的实例选择,例如将大文件写入容量空闲的存储节点。
- 健康检查定制化:Nacos支持TCP、HTTP和MySQL等多种健康检查方式。对于数据处理服务,可以暴露一个“/health”端点,检查其任务队列深度和CPU负载;对于存储服务,可以定期检查磁盘空间和读写权限。确保健康状态能真实反映服务可用性。
- 与网关和流量治理组件集成:将Nacos作为Spring Cloud Gateway、Dubbo或Istio等网关/服务网格的后端服务注册中心。网关可以从Nacos获取最新的服务与实例信息,实现基于路径、头部等规则的路由,将数据处理请求导向特定的处理集群。
四、面临的挑战与展望
尽管Nacos的多级模型优势明显,但在超大规模数据处理场景下,服务实例数量可能极其庞大,对Nacos Server本身的性能和扩展性提出了挑战。Nacos社区正在持续优化其分布式一致性协议和存储层,以支撑百万级别实例的稳定管理。
Nacos的服务多级存储模型通过清晰的层级划分和丰富的治理功能,为数据处理和存储服务构建了一个灵活、可靠、高效的注册与发现基础设施。它不仅简化了服务间的依赖管理,更通过集群化部署和智能路由,直接提升了数据处理管道的性能和韧性,是现代云原生数据架构中不可或缺的一环。
如若转载,请注明出处:http://www.somaodata.com/product/64.html
更新时间:2026-06-19 05:34:56